Paddle Lite深度学习框架 v2.11
Paddle Lite是一个高性能、轻量级、灵活性强且易于扩展的深度学习推理框架,定位支持包括移动端、嵌入式以及服务器端在内的多硬件平台。
当前Paddle Lite不仅在百度内部业务中得到全面应用,也成功支持了众多外部用户和企业的生产任务。
主要特性
多硬件支持:
Paddle Lite架构已经验证和完整支持从 Mobile 到 Server 多种硬件平台,包括 ARM CPU、Mali GPU、Adreno GPU、华为 NPU,以及 FPGA 等,且正在不断增加更多新硬件支持。
各个硬件平台的 Kernel 在代码层和执行层互不干扰,用户不仅可以自由插拔任何硬件,还支持任意系统可见硬件之间的混合调度。
轻量级部署:
Paddle Lite在设计上对图优化模块和执行引擎实现了良好的解耦拆分,移动端可以直接部署执行阶段,无任何第三方依赖。
包含完整的80个 op+85个 Kernel 的动态库,对于ARMV7只有800K,ARMV8下为1.3M,并可以通过裁剪预测库进一步减小预测库文件大小。
高性能:
极致的 ARM CPU 性能优化:针对不同微架构特点实现kernel的定制,最大发挥计算性能,在主流模型上展现出领先的速度优势。
支持 PaddleSlim模型压缩工具:支持量化训练、离线量化等多种量化方式,最优可在不损失精度的前提下进一步提升模型推理性能。性能数据请参考 benchmark。
多模型多算子:
Paddle Lite和PaddlePaddle训练框架的OP对齐,提供广泛的模型支持能力。
目前已严格验证24个模型200个OP的精度和性能,对视觉类模型做到了较为充分的支持,覆盖分类、检测和定位,包含了特色的OCR模型的支持,并在不断丰富中。具体请参考支持OP。
强大的图分析和优化能力:
不同于常规的移动端预测引擎基于 Python 脚本工具转化模型, Lite 架构上有完整基于 C++ 开发的 IR 及相应 Pass 集合,以支持操作熔合,计算剪枝,存储优化,量化计算等多类计算图优化。更多的优化策略可以简单通过 新增 Pass 的方式模块化支持。
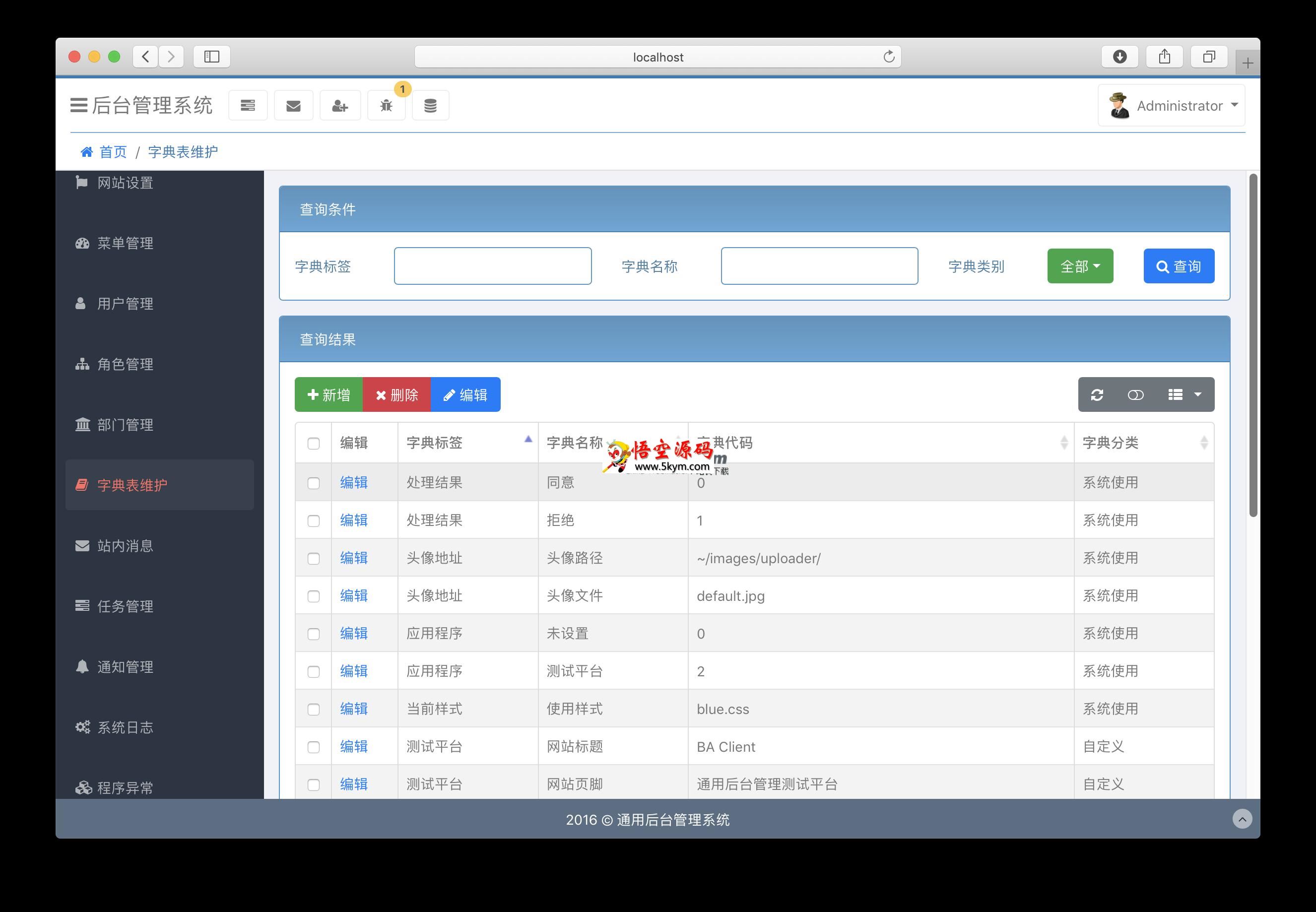
下载列表
版权声明:本文来源于互联网,如有侵权,请联系下方邮箱,一个工作日删除!